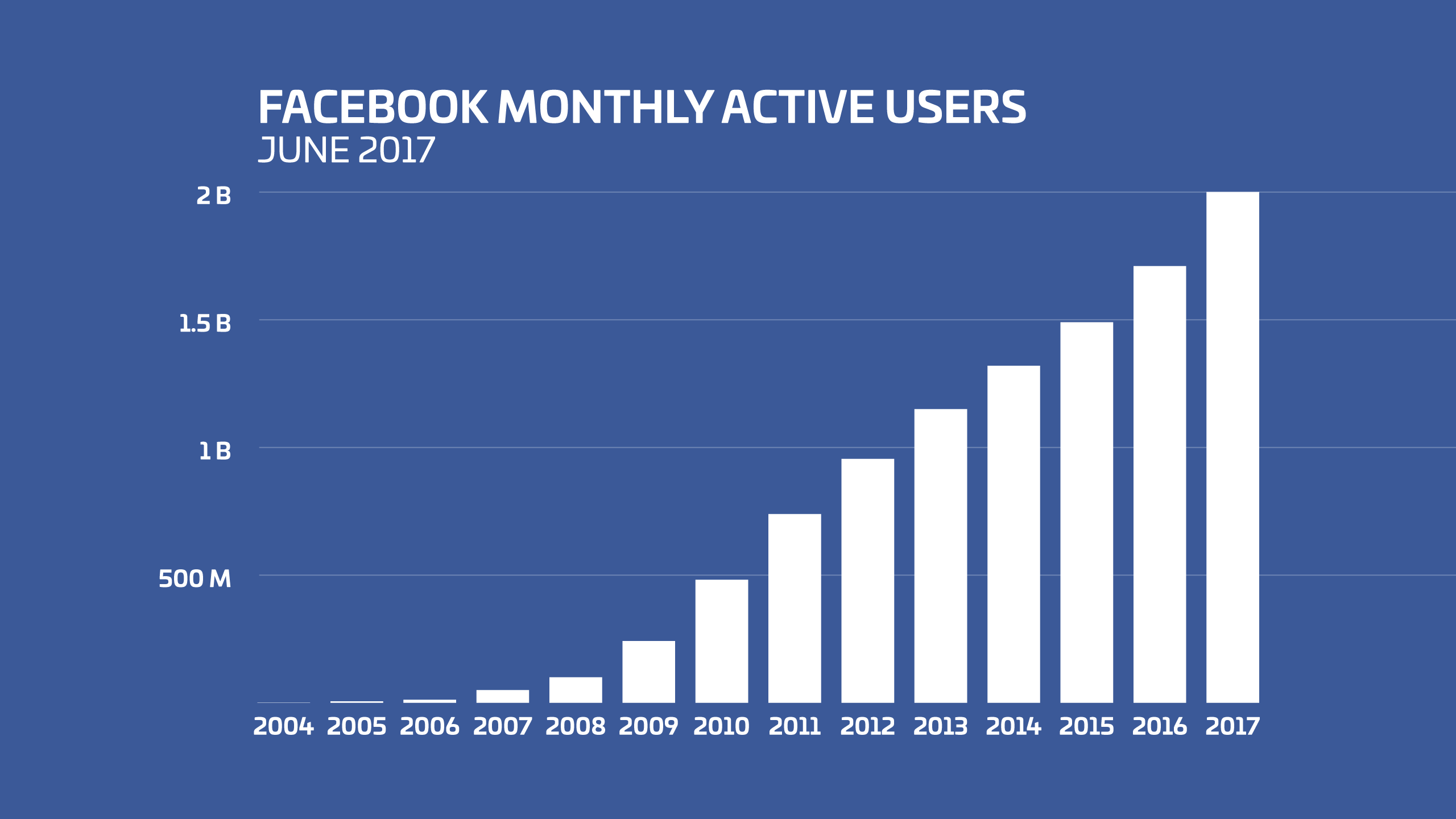
Facebook est aujourd’hui un moyen d’adhérer au monde. Il traduit un certain rapport que l’on a aujourd’hui avec notre environnement, l’impossibilité de vivre les choses directement, sans interface et sans l’artifice d’une technologie. Pour certains utilisateurs, l’usage est dicté par la fascination technologique, le désir de paraitre et l’envie de vivre par procuration.
Comme nous le savons tous, Facebook est l’un des plus grand fleuron de l’industrie du numérique. Ce fait n’est pas seulement dû aux innovations de l’entreprise, mais par une source qu’elle peut monnayer auprès de ses annonceurs et qu’elle obtient gratuitement ainsi qu’en contenu : les données privées de ses utilisateurs.
« La vie privée est la capacité, pour une personne ou pour un groupe de personnes, de s’isoler afin de protéger ses intérêts. » Source :Wikipédia
Malgré les récentes mises à jours de sa politique de sécurité et de divulgation de l’information à des tiers, le site ne renonce en rien à recueillir les informations privées de ses utilisateurs.
Ces données sont transmises à des annonceurs pour cibler des publicités en fonction des caractéristiques détaillées des profils et pour capter des informations sur des personnes qui ne sont pas inscrites sur le réseaux social. La conservation et l’utilisation de ces informations sont également de rigueur pour les utilisateurs ayant résilié leur compte.
Dans une économie totalement marchande, toute donnée privatisée peut faire l’objet de grandes convoitises. Dans ce cadre, pour transformer cette « marchandise » que l’on appelait au siècle dernier, la vie privée, il a fallut mettre en place des stratégies marketing ciblées.
La défense de la publicité est alors évidente pour le groupe car elle concerne une grande partie de ses revenus. Ce fait est argumenté par le fait qu’elle permet aux internautes d’utiliser gratuitement les services. Pas tout à fait, car Facebook vend aux annonceurs les données prélevées auprès de ses utilisateurs, même si ils n’en ont pas forcément conscience.
Plusieurs étapes ont du être franchies avant d’en arriver là. Les utilisateurs souhaitent aujourd’hui valoriser l’exposition de soi. Les réseaux sociaux y sont parvenus à tel point que les utilisateurs gèrent aujourd’hui leurs amours, leurs amitiés ou leur vie entière sur internet.
Facebook est pourtant transparent sur ses intentions : « Vous nous accordez une licence non exclusive, transférable, sous licenciable, sans redevance et mondiale pour l’utilisation des contenus de propriété intellectuelle que vous publiez sur Facebook ». La résiliation du profil ne change en rien la position du groupe.
Facebook recueille également des données personnelles grâce aux cookies déposés sur les machines de ses utilisateurs. Même lorsque les utilisateurs ne sont pas connectés au service, Facebook recueille des informations. Le site s’en défend, est contredit le fait que ce soit une forme d’espionnage : « Nous utilisons ces cookies pour fournir des contenus personnalisés, améliorer notre service ou protéger nos utilisateurs et notre service ».
Son fondateur considère aujourd’hui que« l’ère de la vie privée est révolue et que nous vivons une époque d’exposition n’inquiétant que ceux qui ont des choses à se reprocher ».
Facebook conçoit un site, comparable aux prêches, souhaitant acquérir toujours plus de fidèles et ériger une société à son image. Une société à leur image ? Oui, Facebook a pour intention de créer sa propre monnaie. Quand on sait que chaque empire en a créé pour s’imposer sur la planète et que toute monnaie peut être considérée comme une convention sociale dont la légitimité dépend de celui qui la frappe. On a dorénavant une idée du poids économique et social que représente le site à travers le monde.
Cette monnaie est aujourd’hui utilisée uniquement dans le cadre des jeux en ligne, mais pourrait devenir une source financière sans équivalence pour le site. Facebook souhaite se positionner comme une interface dans laquelle les utilisateurs peuvent consommer et voir tout ce qu’il se trouve sur le web.
Les identités des utilisateurs centralisées en un seul et même lieu, peuvent-elles pousser à la mégalomanie et aux dérives totalitaires ? C’est une question que l’on doit se poser au vu de la puissance et des droits accordés à l’entreprise.
Cet article n’a pas été écrit pour pointer du doigt la politique du site mais pour éveiller les consciencessur l’importance de la préservation et le contrôle de notre vie privée.
Le fondateur du site le dit lui même « les gens se sont non seulement habitués à partager plus d’informations, mais à le faire plus ouvertement et avec davantage de monde. La norme sociale a évolué avec le temps ». Dans un avenir très proche, les nouvelles générations ne connaitront sûrement plus la définition de « vie privée ».
Personne ne peut ignorer les problématiques liées aux dérèglements climatiques. Canicule en été, hiver sans neige, dérèglement du climat, inondations, sécheresses … Les changements climatiques se manifestent sous de nombreuses formes, il ne s’agit pas seulement d’une hausse de la température moyenne à la surface sur globe.
La fonte des glaces fait monter le niveau de la mer, mettant en péril de nombreux archipels et terres basses, comme les Pays-Bas ou le Bangladesh. Le 21ème siècle est le premier siècle à voir l’apparition de réfugiés climatiques.
Certaine personne compte sur l’innovation pour résoudre les effets dus au dérèglement climatique, mais ira t’elle assez vite ? Surtout lorsque l’on observe le boom économique des pays émergents comme la Chine, l’Inde et le Brésil, qui représentent à eux 3 environ 40% de la population mondiale ? Que se passera-t-il quand la Chine sera un pays développé à l’image des États-Unis, qui en 2007 rejetaient 5 fois plus de CO2 par habitant que la Chine ?
Google :
Une série de conférences ont été organisées lors de l’évènement SciFoo, au sein des locaux de Google. Cet évènement a rassemblé une poignée de scientifiques traitant de la fin possible de l’histoire humaine d’ici moins d’un siècle.
Une hypothèse potentielle, qui découle d’analyses scientifiques et logiques de la situation actuelle et notamment du réchauffement climatique. Nous sommes au bord d’un changement majeur dans l’histoire de l’humanité.
Le Deepmind :
« Les données nombreuses et omniprésentes dans nos smartphones et nos objets connectés constituent une formidable matière première pour produire de l’innovation bénéfique pour le climat », Arnaud Legrand, président d’Energiency
DeepMind, filiale de Google, est une société spécialisée dans l’apprentissage automatique et dans les neuroscience des systèmes. Cette société a annoncé sa volonté de collaborer avec les universités américaines afin de développer la recherche en matière de réchauffement climatique.
Le processus d’apprentissage du « Machine Learning » est au coeur des recherches. Google avait déjà chargé DeepMind de réduire l’énergie consommée par ses gigantesques bases de données de plus de 40%. En effet, le coût écologique des data-centers est énorme. Une recherche sur Google équivaudrait à une ampoule électrique allumée pendant une heure.
Deepmind et le Royaume-Uni :
DeepMind souhaite également utiliser des algorithmes pour diminuer la consommation d’électricité au Royaume-Uni. En 2014, le Royaume-Uni a consommé plus de 330 térawattheures d’énergie. Toute réduction de cette consommation aura pour impact de réduire les dépenses des consommateurs mais également de réduire les émissions de dioxyde de carbone. Ces émissions étant l’une des principales cause du réchauffement climatique.
Deepmind pense à de nombreux paramètres qui pourraient être utilisés pour arriver à une baisse de la consommation : à la météo, aux besoins énergétiques d’une région, aux types d’énergies utilisées et à la prédiction de pics de demandes et d’offres dans le domaine de l’énergie.
Le « Big data » :
Les nouvelles technologies permettent de nombreuses innovations dans le cadre de la réduction des émissions des gaz à effet de serre dues aux activités humaines. Energiency est une start-up qui développe des algorithmes permettant aux entreprises d’optimiser leur consommation d’énergie en analysant en temps réel les données issues de compteurs électriques connectés. Climate Change Challenge, a pour objectif de mobiliser l’intelligence collective et les données ouvertes, l’open data, pour imaginer des solutions contre le changement climatique.
L’open data est une source essentielle en matière de développement durable. On retrouve ces données dans le partage d’informations sur des catastrophes naturelles. L’analyse du « Big Data » allié à nos objets connectés et à leur géolocalisation constitue une solution potentielle afin de prédire la survenue d’une catastrophe naturelle et d’analyser son évolution en temps réel.
Un autre impact visible dès à présent est celui de la disparition de la diversité des espèces, qui doivent s’adapter à de nouvelles conditions ou bien migrer en raison de la hausse des températures. Le « Big Data » peut apporter, là encore, une solution dans la compréhension des phénomènes dynamiques liés à l’évolution du climat.
Pour conclure :
Les effets dus aux dérèglements climatiques sont aujourd’hui visibles. Il est donc de notre responsabilité de trouver des solutions permettant d’y remédier. Aujourd’hui, le réchauffement du globeest la plus grande menace pour la sécurité mondiale. Il menace la paix, la prospérité, les villes et les milliards de personnes qui y résident.
De nombreuses starts-up ont vu le jour, ainsi que de nombreuses initiatives de la part des entreprises et des états pour réduire leur consommation d’énergie. Résoudre les problèmes climatiques n’est pas qu’une question de politique, mais de survie de l’humanité. L’intelligence artificielle et le « big data » sont donc, dès aujourd’hui, des solutions envisageables et concrètes pour nous aider à y parvenir.
L’homme classe et quantifie des informations sous forme de tableaux depuis des siècles. Les améliorations apportées à la technologie ont simplifié l’accès et la collecte de données, tandis que le web permet d’y accéder en continu.
Aujourd’hui, les bases de données sont de plus en plus volumineuses, on parle de “Big Data”. Il s’agit d’une explosion quantitative de la donnée numérique. Les perspectives du traitement de ces données sont encore insoupçonnées. On évoque de nouvelles possibilités d’exploration de l’information : l’analyse tendancielle, climatique, environnementale, sociopolitique, de la sécurité et de la lutte contre la criminalité, de phénomènes religieux, culturel et politique. Cette agrégation de données a entraîné la création d’un véritable écosystème économique impliquant les plus importants acteurs du secteur des technologies de l’information.
Cette richesse de données peut-être une mine d’informations pour aider à l’amélioration de la prise de décision, à la mise en évidence de constats, à la transmission d’idées plus claires, et à avoir un regard objectif sur notre environnement.
La datavisualisation, c’est quoi ?
La datavisualisation est l’utilisation de représentations graphiques de données, interactives ou statiques, qui ont pour but d’amplifier les processus cognitifs. Ces processus sont :
La perception
La mémoire
Le raisonnement
L’apprentissage
Les représentations visuelles structurent le raisonnement des individus par le biais de la connaissance commune (comparaisons, quantités, formes, volumes) afin d’interpréter des données. Le traitement d’informations, complexes et/ou denses, est alors facilité, voir immédiat.
Les objectifs de la datavisualisation
La datavisualisation doit retenir l’intérêt de ses interlocuteurs, à travers une histoire. Elle doit enrichir leur culture commune sur un thème caractérisé et identifiable. Elle a pour finalité de convaincre ses interlocuteurs, de les inviter à agir, de les éclairer, d’enrichir leurs connaissances ou de les inviter à se remettre en question sur une vision de la réalité grâce à des données rationnelles et objectives.
Les données sont une représentation de la vie réelle, tout est quantifiable. Indépendamment de son format, de son esthétisme, de sa présentation, la datavisualisation a pour objectif de montrer ce que les données ont à dire.
Finalement, l’objectif de la datavisualisation est de :
Faire parler des données brutes
Synthétiser les enjeux essentiels d’un set de données
Traduire visuellement des données
Les modèles de représentations
Dans un premier temps, l’auteur d’une représentation de données doit vérifier la véracité des données collectées, quelque soit sa source d’approvisionnement. Vous pouvez embellir autant que vous voulez votre représentation, les données en sont l’essence.
L’auteur doit avoir un oeil critique vis à vis de ses données, et définir un but graphique ainsi qu’un public cible. La représentation, par l’intermédiaire de représentations cognitives, doit apporter une vision claire d’un constat. Vous pouvez ainsi créer une représentation claire et qui mérite que le lecteur y consacre de son temps.
Avec toutes les options de visualisation, il peut être difficile de déterminer quel graphique convient mieux à vos données. Voici une présentation des types de représentations et leurs usages.
Visualisation temporelle
Le temps est intégré à notre vie quotidienne, les choses changent et évoluent dans le temps. La visualisation temporelle est donc une représentation très intuitive pour un public cible. Elle permet d’avoir un rapide aperçu général des données sur un temps donné. Elle peut être utilisée comme un outil d’exploration au sein de sections temporelles.
Les variations temporelles sont la base de votre histoire. Pourquoi y a t-il tel ou tel pic ? Pourquoi y a t-il telle ou telle chute ? L’intérêt est de mettre en évidence les parties intéressantes de la représentation pour votre auditoire
Visualisation des proportions
Les données relatives aux proportions sont regroupées par catégories et sous-catégories. Grâce au traitement des données par proportions, on cherche à avoir un maximum, un minimum et une distribution globale.
La visualisation des proportions représente les parties d’un tout. Chaque valeur individuelle a une signification particulière. Les proportions mettent en relation les données les unes entre les autres en conservant l’impression d’un tout.
Visualisation des relations
La recherche de relation entre les données peut-être un réel défi et nécessite une plus grande réflexion critique. Dans certains cas, elle peut révéler davantage d’informations. Vos données s’associent et interagissent entre elles et définissent l’histoire que vous allez raconter.
L’auteur doit chercher la corrélation entre différentes données et ainsi baser son histoire sur leur coexistence dans un environnement commun. Il faut chercher ce à quoi les données se réfèrent dans un contexte identifié. Puis, tirer des constats sur les relations qu’entretiennent ces données. Il faut donc méditer sur le contexte des données et les explications possibles sur tel ou tel constat déterminé.
Visualisation des différences
La comparaison d’une seule variable est plutôt aisé : “Une maison possède une surface plus grande qu’une autre”. Qu’en est-il si il y a une centaine de maisons à classer ? Qu’en est-il si pour chacune des maisons, on doit considérer plusieurs variables, comme le nombre de chambre, la superficie du jardin ou le montant des impôts locaux ?
La comparaison devient plus complexe. D’où l’usage de la visualisation des différences permettant de comparer les variables essentielles d’un sujet donné et tirées d’un set de data beaucoup plus important.
Pour conclure
Le cerveau humain est capable de traiter une image 60 000 fois plus vite qu’un texte. Plus les données sont nombreuses et compliquées, plus il est donc intéressant de les traduire en visuels. En amont de la conversion des données en visuels, il faut sélectionner les données intéressantes, les plus justes et les plus importantes.
Aujourd’hui, la surcharge des données entraîne une confusion globale sur leur traitement. Ces données sont éparpillées dans des feuilles de calcul, des bases de données, des espaces de stockage au sein de multiples services, sur Internet. Leur interprétation devient très difficile. La comparaison, à travers des tableaux de données brutes, exige un effort d’abstraction et de mémoire qui n’est plus atteignable à partir d’un certain volume de données.
Le but de la datavisualisation est d’aller à l’essentiel et son enjeu est d’appuyer la prise de décision. Il est donc crucial d’être juste, précis et avant tout respectueux de la réalité.
Sources : Data visualisation — De l’extraction des données à leur représentation graphique. (Auteur(s) : Nathan Yau, Editeur(s) : Eyrolles)
Depuis ces 10 dernières années, nous avons pu constater l’explosion quantitative de la donnée numérique qui nous a contraint à de nouvelles manières de voir et d’analyser notre monde. Le « Big Data » désigne un volume de données tellement conséquent, qu’il devient difficile de les traiter avec des outils classiques de gestion de base de données ou de gestion de l’information. Le « Big Data » a participé très largement à l’émergence de l’intelligence artificielle.
“L’impact à court terme de l’intelligence artificielle dépend de qui la contrôle. Et, à long terme, de savoir si elle peut être tout simplement contrôlée.” Stephen Hawking
Tous les jours, nous enrichissons ce « Big Data » en mettant en ligne des milliers de contenus gratuitement sur le web. Aujourd’hui, en l’espace de 10 secondes :
Mais l’intelligence artificielle n’est pas qu’une affaire de données. La puissance de calcul des ordinateurs et nos connaissances sur le fonctionnement du cerveau humain ont fortement fait progresser les recherches, d’où l’engouement aujourd’hui pour cette technologie avec des découvertes toujours plus stupéfiantes.
L’intelligence artificielle
« L’intelligence artificielle est une discipline scientifique recherchant des méthodes de résolution de problèmes à forte complexité logique ou algorithmique. Par extension, elle désigne, dans le langage courant, les dispositifs imitant ou remplaçant l’humain dans certaines mises en œuvre de ses fonctions cognitives. » (source Wikipédia)
L’objectif de l’intelligence artificielle est de reproduire les principales caractéristiques de l’homme qui sont la perception, le langage, la mémoire, le raisonnement, la décision, le mouvement. Il faut distinguer deux types d’intelligence artificielle :
Forte : Elle désigne une machine qui a une réelle conscience de soi, de vrais sentiments et une compréhension de ses propres raisonnements.
Faible : Elle désigne des algorithmes capables de résoudre des problèmes. La machine simule l’intelligence, elle semble agir comme si elle était intelligente mais elle ne l’est pas.
Lorsque l’on a construit le premier avion, on n’a pas cherché à reproduire le comportement d’un oiseau. On s’en est inspiré, on a utilisé les principes de la physique pour atteindre le même résultat. Avec l’intelligence artificielle, c’est la même chose. On va s’inspirer des caractéristiques que l’on comprend de l’intelligence naturelle et ce qui va nous être utile pour atteindre le même résultat.
Même si l’évolution humaine a une large avance sur les machines, elles nous ont déjà dépassés dans certains domaines. L’objectif de Google DeepMind, entreprise spécialisée dans l’intelligence artificielle et notamment le principe du Deep Learning, est de « résoudre l’intelligence ». De nombreux experts ne doutent pas de la capacité des machines à arriver un jour au même niveau intellectuel que les humains, alors que d’autres pensent que c’est totalement impossible.
En 2016, les meilleurs joueurs d’échecs et de go ont été battus par une intelligence artificielle, AlphaGo, conçue par le groupe Google Deepmind. Au-delà de cette performance, il faut se rendre à l’évidence que plus aucun humain ne pourra devenir le meilleur à l’un de ces jeux. Peu importe à quel point vous vous entraînez, même si vous dédiez votre vie à devenir le meilleur, cela ne sera jamais assez. Heureusement pour nous, la condition humaine est faite de bien plus que de jeu d’échecs ou de go. Mais est-il si incertain que d’autres talents ou capacités plus générales pourraient devenir obsolète ?
Isaac Asimov, écrivain visionnaire en matière de science fiction, a dévoilé dans sa nouvelle « Cercle Vicieux » en 1942, les trois lois de la robotique :
1. Un robot ne peut porter atteinte à un être humain.
2. Un robot doit obéir aux ordres qui lui sont donnés par un être humain.
3. Un robot doit protéger son existence tant que cette protection n’entre pas en conflit avec la première ou la deuxième loi.
Google a inscrit ces trois lois dans son en-tête, étant conscient qu’elles seraient bientôt applicables et seraient le fondement de leur objectif final en matière d’intelligence artificielle, qui est de créer une intelligence forte capable de penser d’elle même.
L’intelligence artificielle dans le cadre de la recherche
« Un moteur de recherche est une application web permettant, de trouver des ressources à partir d’une requête sous forme de mots. Les ressources peuvent être des pages web, des articles des forums, des images, des vidéos, des fichiers, etc.. » (source Wikipédia)
L’objectif de l’intelligence artificielle est de comprendre ce qu’il y a derrière une requête. Chaque être humain définit une requête en fonction de son humeur, d’un contexte, de centres d’intérêts, d’un comportement et finalement de l’usage qu’il fait d’un moteur de recherche.
L’intérêt est d’identifier l’intention de recherche de l’utilisateur ainsi que le sens de la requête et non le sens des mots-clés pris séparément comme dans un dictionnaire. Il faut donc étudier la relation des mots et le sens qu’ils ont les uns à côté des autres.
Les réseaux de neurones artificiels
La recherche est de plus en plus pensée comme un réseau de neurones. L’idée est de simuler de l’intelligence par l’apport de données. Les réseaux de neurones visent à reproduire approximativement le fonctionnement des neurones vivants. Un neurone artificiel est capable de faire des calculs à partir de quelques données en entrées et de générer un résultat en sortie.
La connaissance est acquise via les connexions entre neurones. L’objectif est d’être aussi fidèle que possible au fonctionnement des neurones naturels. Les réseaux neuronaux vont ensuite permettre de résoudre des problèmes. Il faut imaginer le moteur de recherche comme un cerveau, qu’il faut sans cesse alimenter en données pour le rendre plus autonome. L’idée est d’imiter les mécanismes du cerveau humain :
L’auto apprentissage
Le raisonnement
L’analyse
La mémorisation
La contextualisation
Les algorithmes ne jouent qu’à 20% dans la qualité des prédictions, les 80%autres sont dus à la qualité des données. Plus l’on va avoir de données quantitatives et qualitatives, plus l’on va pouvoir anticiper les recherches des utilisateurs et mieux répondre à leur besoin.
Le « Machine Learning »
Le « Machine Learning » est une forme d’intelligence artificielle qui permet aux machines d’apprendre de manière autonome. Ces programmes informatiques sont capables d’évoluer en présence de nouvelles données. » (source Wikipédia)
L’algorithme de Google, RankBrain, a la capacité d’apprendre et de comprendre les requêtes des utilisateurs du moteur de recherche Google. La dimension d’apprentissage automatique doit permettre d’interpréter des recherches complexes et de nouvelles recherches, correspondant à 15% des recherches sur Google.
Google peut aller au delà du sens premier des mots. Il s’appuie sur leurs sens et leurs synonymes. En assemblant ces informations, le moteur affine le sens et traite, en temps réel, l’information. A la clé, une information plus pertinente, puisque contextualisée.
Le « Deep Learning
« La technologie du « Deep Learning » donne le moyen à une machine de représenter le monde. C’est une machine virtuelle composée de milliers d’unités, les neurones, qui effectuent chacun de petits calculs simples. » (Source : Wikipédia)
C’est une méthode phare de l’intelligence artificielle. De grandes entreprises y investissent des fortunes : Google, IBM, Microsoft, Amazon, Yandex et Baidu. Le « Deep Learning » et les expériences qui en résultent sont les prémices d’une intelligence forte, capable de réfléchir et d’apprendre par elle-même.
Google Brain a été capable de « découvrir », par lui-même, le concept de chat. La machine a analysé, pendant trois jours, dix millions de captures d’écran tirées de YouTube. A l’issue de cet entraînement, le programme avait appris lui-même à détecter des têtes de chats.
Aujourd’hui, ce principe est utilisé dans Google maps pour détecter le nom de rue dans les images. La machine est capable dans n’importe quel contexte d’identifier et de nommer un objet, un humain, une forme. Dans une échéance de 10 ans, cette technologie va être présente dans toute l’électronique de notre quotidien. Dans les voitures, les avions ou encore l’assistance au diagnostic de médecins.
Le futur de la recherche
20%des requêtes faites sur Android et 1/4 des recherches faites avec Bing dans Windows 10 aux U.S. sont des recherches vocales.
L’avenir du search passera par la recherche vocale et les assistants personnels virtuels. Siri, Google Now, Cortana ou même Alexa ont fait des progrès considérables dans la compréhension des demandes formulées.
Aujourd’hui, les recherches vocales sont très basiques, mais il s’agit d’un gros volume de recherche. Ce n’est donc pas un phénomène temporaire, il s’agit d’une tendance lourde de la recherche qui tant à se développer. La complexité des recherches vocales sera toujours limitée par la faculté de compréhension des interfaces, mais des progrès ont été réalisés. Les interfaces vocales de Google et Baidu atteignent des taux de pertinence proches de 95%.
Les interfaces vocales ne sont pas présentes uniquement dans les smartphones, elles sont également utilisées par une nouvelle génération de terminaux connectés :
Casque de réalité virtuelle
TV
Voiture
Pour conclure
“Je pense que nous devrions faire très attention avec l’intelligence artificielle. Si je devais imaginer quelle serait notre plus grande menace existentielle, c’est probablement ça.” Elon Musk
Tous ces nouveaux progrès montrent que l’humanification des machinesest en marche avec peut-être un jour l’émergence d’une intelligence forte. Les recherches faites sur un clavier avec des pages de résultats ont encore de belles années devant elles, mais il faut nous préparer à faire la transition vers ces nouveaux supports et usages.
L’intelligence artificielle d’Amazon, Alexa, illustre concrètement la tendance que la recherche tend à être un véritable assistant personnel, sans interface physique entre l’homme et la réponse qu’il souhaite obtenir. Le fait de taper une recherche dans un moteur et de passer du temps à chercher une réponse sera peut-être à court terme un lointain souvenir.
L’information, avant la numérisation du monde, était diffusée via des supports physiques fiables et rédigée par des personnes disposant d’une fonction particulière leur donnant le droit de transmettre de l’information. L’information, avant la numérisation du monde, était diffusée via des supports physiques fiables et rédigée par des personnes disposant d’une fonction particulière leur donnant le droit de transmettre de l’information.
Aujourd’hui, toutes personnes ayant accès à Internet peut diffuser de l’information qui sera à la suite corrigée, modifiée ou encore enrichie.
L’information n’ait plus diffusé dans un cadre strictement défini et contrôlé. La presse ne détient plus le monopole de la transmission de l’information. De nos jours, cette information est diffusée sur des supports virtuels et des supports physiques. La numérisation du monde a entrainé de grands changements et notamment a fait apparaître un modèle économique ancien, utilisé encore par la presse. Cette numérisation a changé le comportement des consommateurs vis à vis de l’information. Les règles mises en place, par les quotidiens, visant à transmettre une information de qualité, rédigée par des professionnels est en train de disparaître au sein des supports virtuels. La numérisation du monde est donc en train de modifier un environnement stable et homogène qu’était la presse auparavant.
La numérisation du monde a entrainé des changements dans le mode de consommation des lecteurs de l’information. La planète média est vue comme une “météorite internet“, un corps spatial imprévu et vaste. L’éventuelle disparition des journaux traditionnels dans un futur proche est annoncée, elle est comparée à la crise Crétacé-Tertiaire qui provoqua la disparition des dinosaures. Cette conséquence est due au modèle économique ancien utilisé par les quotidiens.
La pratique journalistique est à reconstruire et à réinventer. Internet a modifié les comportements des individus mais aussi l’élément renfermant l’ensemble des informations nécessaires au développement et au fonctionnement d’un quotidien qui est son ADN.
Le choc est tel qu’il atteint la radio et la télévision notamment les chaînes d’informations en continu. Internet ne peut pas être considéré comme un média car c’est un espace communautaire. Cet outil permet aux internautes de visualiser les informations transcrites par l’intermédiaire de professionnels qualifiés mais peuvent aussi générer leurs propres informations. Grâce à l’arrivée du haut débit et du web 2.0, l’internaute devient l’un des principaux acteurs diffusant du contenu sur Internet. Chaque individu peut disposer d’un espace considéré comme une « Une » dans laquelle il peut générer du contenu. Il n’y a donc aucun contrôle mis en place permettant d’affirmer l’intégrité de l’information. Cette information présente sur le web est principalement transcrite par les internautes. Le web permet d’avoir accès à un flux d’informations continu, régulié et surtout en temps réel.
Les internautes corrigent, modifient, enrichissent sans cesse chaque heure, chaque instant l’information diffusée à l’état brut.
Les nouvelles technologies ont fait naître chez les internautes de nouveaux besoins, ils veulent être lus et écoutés. L’information ne circule plus à sens unique, les personnes publient de l’information, comme les quotidiens traditionnels.